Data Formats Web Scraping
Jorge Cimentada
Data Formats for Webscraping
- Most web scraping involves parsing XML or HTML.
- XML is for data storage and transfer, HTML for website structure.
- Use
xml2package in R to read both formats.
What? What do you mean?
Data Formats for Webscraping: XML
library(xml2)
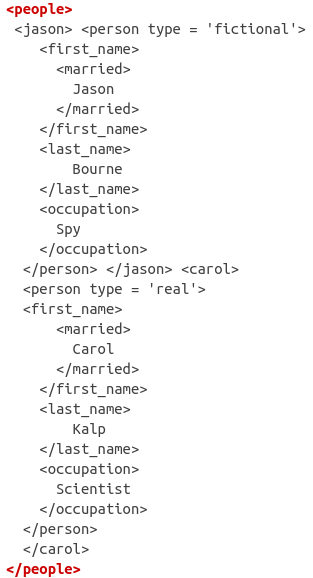
xml_test <- "<people>
<jason>
<person type='fictional'>
<first_name>
<married>
Jason
</married>
</first_name>
<last_name>
Bourne
</last_name>
<occupation>
Spy
</occupation>
</person>
</jason>
<carol>
<person type='real'>
<first_name>
<married>
Carol
</married>
</first_name>
<last_name>
Kalp
</last_name>
<occupation>
Scientist
</occupation>
</person>
</carol>
</people>
"Data Formats for Webscraping: XML
Data Formats for Webscraping: XML

Data Formats for Webscraping: XML
Data Formats for Webscraping: XML
XML tags have a beginning and end, with the end being signified by ‘</>’
XML tags can have any meaning, while HTML has standard tags for website structure.
XML and HTML have many differences, some conceptual and some visible to users, and the author will focus on the most important ones for web scraping in the rest of the chapter.
Data Formats for Webscraping: HTML
Let’s compare:
Data Formats for Webscraping: HTML
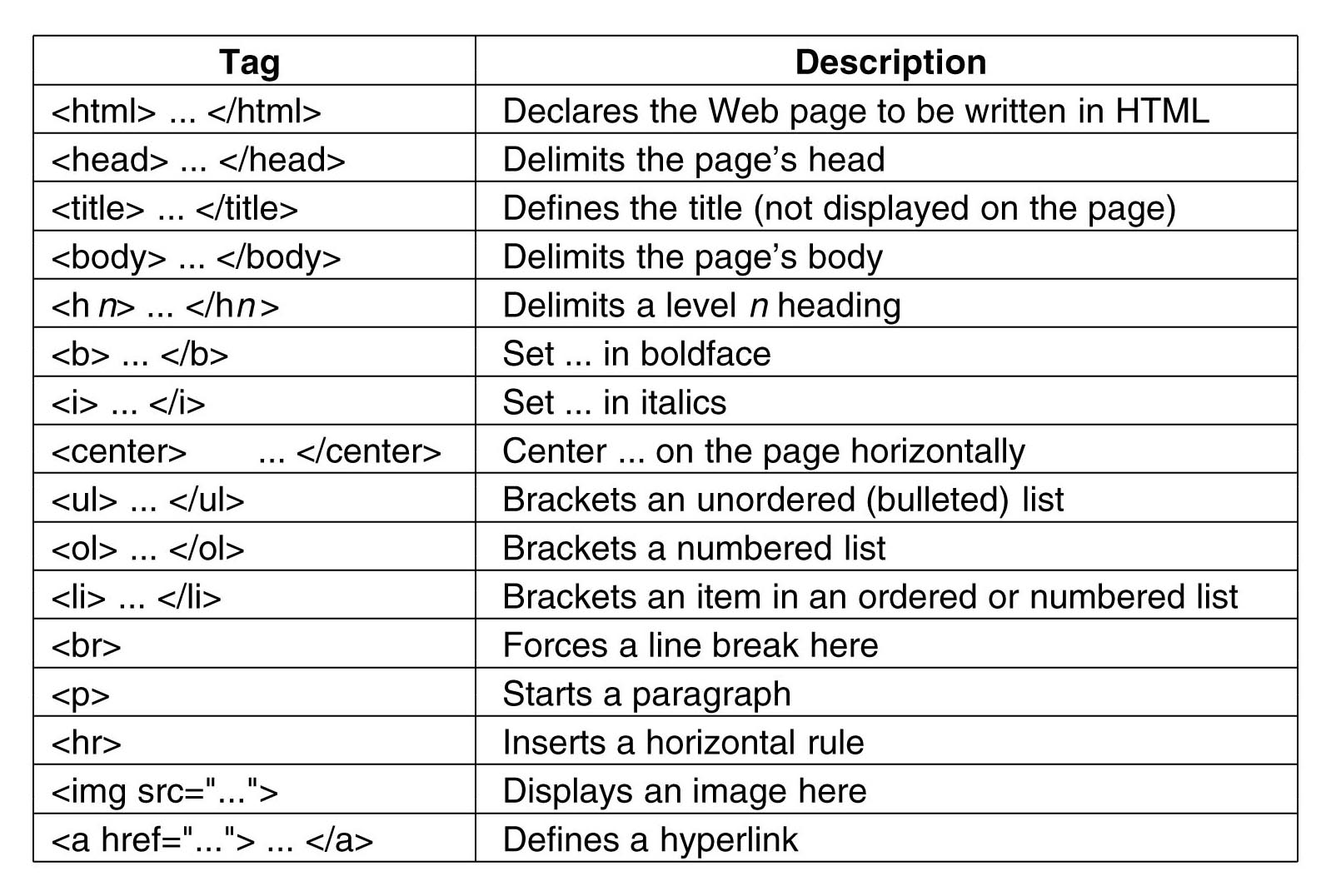
HTML tags have specific properties that structure how a website is shown on a browser
These tags like
<div>,<head>,<title>have predetermined behavior to format the websiteThe tags themselves are standard across the HTML language and have specific behavior for website formatting.
For example…
Data Formats for Webscraping: HTML
Data Formats for Webscraping: HTML
Data Formats for Webscraping: HTML
In XML, all tags must have a closing tag, while some HTML tags don’t need to be closed.
There are too many standard HTML tags for one to remember when getting started.
XML tags have no meaning other than what the creator intended for them.
HTML tags have predetermined behavior and standard across the language.
Data Formats for Webscraping
Data Formats for Webscraping
Data Formats for Webscraping
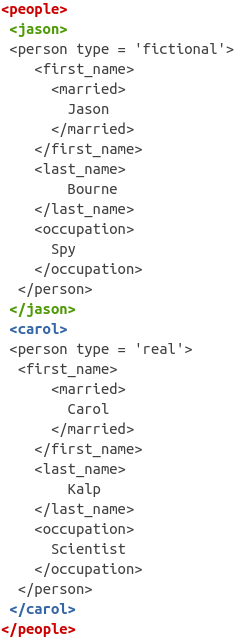
In more detail, the structure is as follows:
The root node is
<people>The child nodes are
<jason>and<carol>Then each child node has nodes
<first_name>,<married>,<last_name>and<occupation>nested within them.
Data Formats for Webscraping
{xml_node}
<jason>
[1] <person type="fictional">\n <first_name>\n <married>\n Jason\n ...{xml_node}
<carol>
[1] <person type="real">\n <first_name>\n <married>\n Carol\n ...Tag attributes
Tags can also have different attributes which are usually specified as <fake_tag attribute='fake'> and ended as usual with </fake_tag>
[[1]]
named character(0)
[[2]]
named character(0)No attribute? Right!
{xml_nodeset (2)}
[1] <jason>\n <person type="fictional">\n <first_name>\n <married>\n ...
[2] <carol>\n <person type="real">\n <first_name>\n <married>\n ...Do these tags have an attribute? No, because if they did, they would have something like <jason type='fake_tag'>
Tag attributes
# We go down one level of children
person_nodes <- xml_children(child_xml)
# <person> is now the main node, so we can extract attributes
person_nodes{xml_nodeset (2)}
[1] <person type="fictional">\n <first_name>\n <married>\n Jason\n ...
[2] <person type="real">\n <first_name>\n <married>\n Carol\n ...Tag attributes
You can even extract the address of specific tags:
# Specific address of each person tag for the whole xml tree
# only using the `person_nodes`
xml_path(person_nodes)[1] "/people/jason/person" "/people/carol/person"---
{xml_nodeset (1)}
[1] <person type="fictional">\n <first_name>\n <married>\n Jason\n ...Same as:
xml_raw %>% xml_child(search = 1).For deeply nested trees,
xml_find_allwill be better.
Tag attributes
HTML also has tag attributes:
Tag attributes
How to separate XML from HTML?
---
Conclusion
XML and HTML are tag-based and have parent-child relationships
XML tags have special meanings while HTML tags have behavior
Navigating nodes in XML and HTML can be done with
xml_child,xml_childrenandxml_find_allExtracting attributes and text is done with
xml_attrandxml_textHTML is more commonly used in web scraping because it is designed to show website format.
Homework
Complete the exercises of chapter 2/3
Read and complete exercises of chapter 4 and 5
Start finding a partner for your group. Here.