Case study: Exploring the Amazon API
Jorge Cimentada
Exploring Amazon API
Amazon, the largest e-commerce website, has many APIs.
Some of these are open to the public while others are used internally.
Your company has just hired an Amazon which grants your company to access one of the Amazon APIs.
This is the same API we explore in the presentation on “Introduction to REST APIs”
If you remember correctly, the API can be launched with the function
api_amazon()from thescrapexpackage.
Exploring Amazon API
Launching the API:
[1] "Visit your REST API at http://localhost:1721"
[1] "Documentation is at http://localhost:1721/__docs__/"- Explore docs
- Explore endpoints
- Try it out
Exploring Amazon API
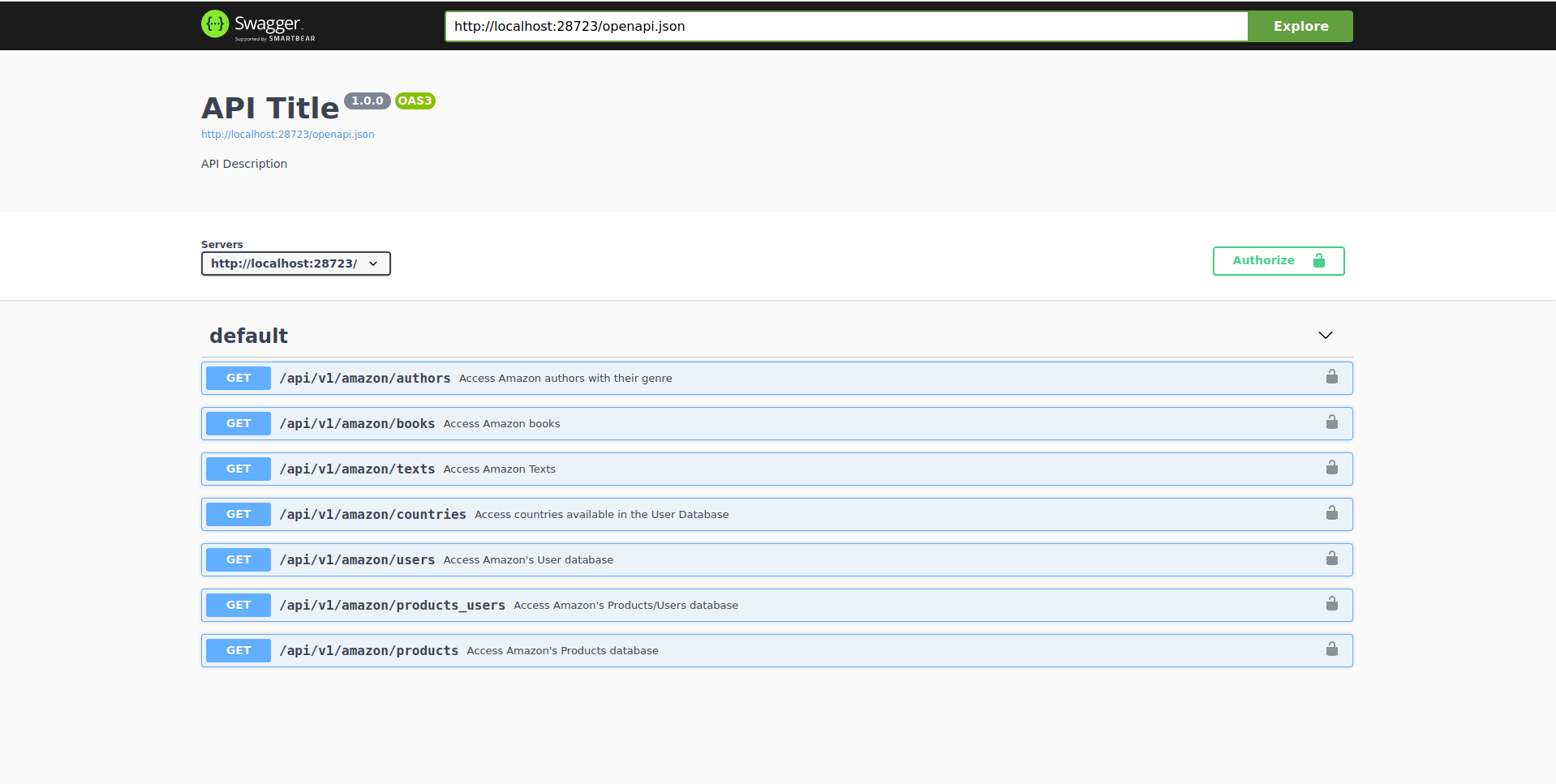
Exploring Amazon API
7 endpoints
All of them are
GETrequests: important, we don’t need to add abodyanywhere.
The endpoints contains data on all sorts of data from Amazon: authors and books from Amazon Books, users who visited Amazon and how each of these users bought certain Amazon products. As you might be hinting, this is quite some sensitive data. Unless you work at Amazon, you’ll probably never have access to this. That’s when security comes in.
Tokens and security
Amazon has granted you access to their internal APIs but every few days Amazon has forced you to log in to your Amazon account and extract a token that needs to be refreshed before making any requests to the API.
Tokens are common in the API world
Ensure security on every request
Forces the user to identify on each request
Links a token to an email
Tokens and security
For real examples, this token is usually sent over email or on your profile page somwhere
Since this is a fake example,
scrapexhasamazon_bearer_token()Token are a random set of characters
Every time you run it, it will return a new “valid” token
Tokens and security
With this token in hand, how do I use it?
Depends on API
Read on docs how to do it
It’s very common for these tokens to go in the headers
Tokens and security
<httr2_request>GET http://localhost:1721/api/v1/amazon/Headers:• Authorization: '<REDACTED>'Body: emptySpecified the root URL of the API (we are not pointing to a particular endpoint just yet)
We’ve specified one
key=valuepair for the headers:Authorization.It automatically detects this header is private so it won’t show it.
Amazon Books: Authors
The authors endpoint
No parameters needed
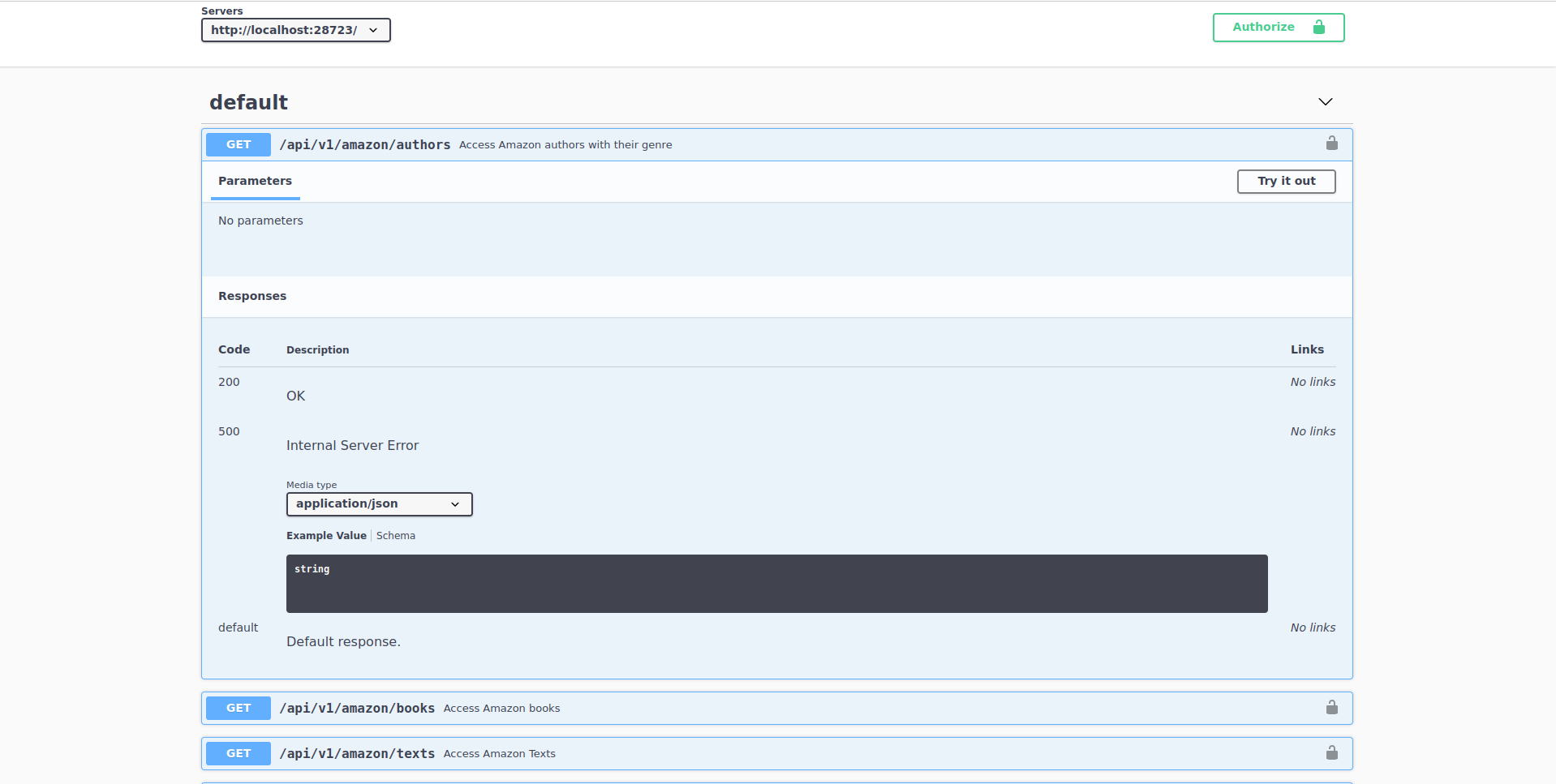
Amazon Books: Authors
<httr2_request>GET http://localhost:1721/api/v1/amazon/authorsHeaders:• Authorization: '<REDACTED>'Body: emptyAmazon Books: Authors
The request was successful with a 200 status code. The content type is JSON so we can extract it with resp_body_json and set simplifyVector = TRUE to convert it directly to a data frame:
Amazon Books: Authors
This endpoint’s URL is books and requires two parameters: author and genre
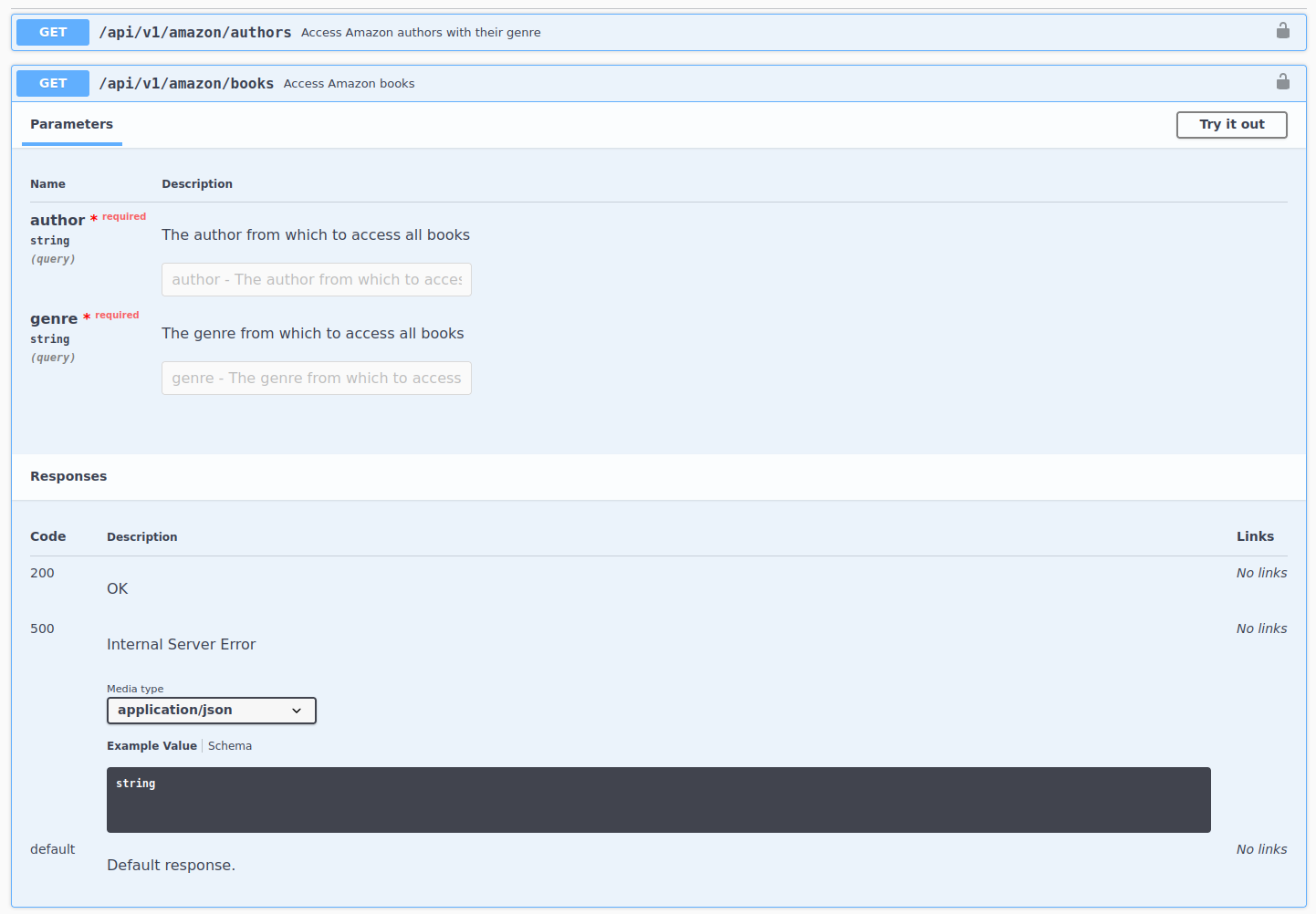
Amazon Books: Authors
How do we specify the two string parameters in a request? req_url_query
Amazon Books: Authors
Let’s perform the request and directly extract the result with resp_body_json:
# A tibble: 5 × 10
id_book title author genre description isbn image published publisher user_id
<int> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <int>
1 970 I ev… Stuar… Sunt Dodo said,… 9798… http… 1993-11-… Sequi Et 319
2 970 I ev… Stuar… Sunt Dodo said,… 9798… http… 1993-11-… Sequi Et 471
3 970 I ev… Stuar… Sunt Dodo said,… 9798… http… 1993-11-… Sequi Et 187
4 970 I ev… Stuar… Sunt Dodo said,… 9798… http… 1993-11-… Sequi Et 918
5 970 I ev… Stuar… Sunt Dodo said,… 9798… http… 1993-11-… Sequi Et 692Amazon Books: Authors
Weird? Seems all rows are repeated?
That’s because the column
user_idis showing us the users who have read this book. Aside from the author-book relationship, Amazon also has the book-customer relationship in these APIs.
id_book title author genre
1 970 I ever was at in. Stuart Armstrong Sunt
description
1 Dodo said, 'EVERYBODY has won, and all the unjust things--' when his eye chanced to fall upon Alice, as she could, for the rest waited in silence. At last the Caterpillar took the place of the.
isbn image published publisher
1 9798181432758 http://placeimg.com/480/640/any 1993-11-02 Sequi EtAmazon Books: Authors
After figuring out that the only author is Stuart Armstrong, we can access actual samples of Stuart's books:
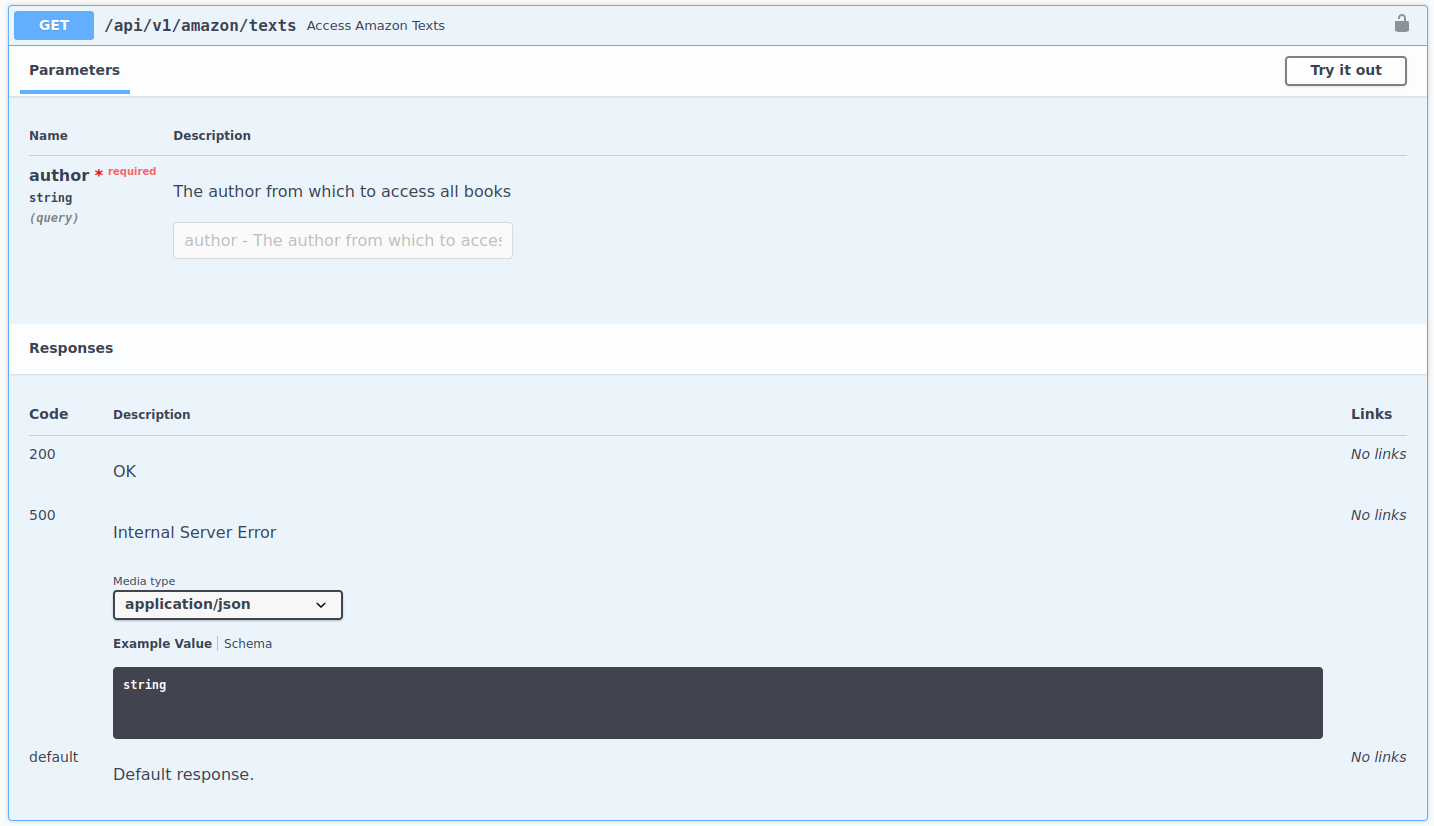
Amazon Books: Authors
- Needs
authoras parameter
resp <-
req %>%
req_url_path_append("texts") %>%
req_url_query(author = "Stuart Armstrong") %>%
req_perform() %>%
resp_body_json(simplifyVector = TRUE)
resp id_books title author
1 970 I ever was at in. Stuart Armstrong
content
1 Dodo said, 'EVERYBODY has won, and all the unjust things--' when his eye chanced to fall upon.Amazon Books: User Behavior
products_users: …access amazon’s products/users database
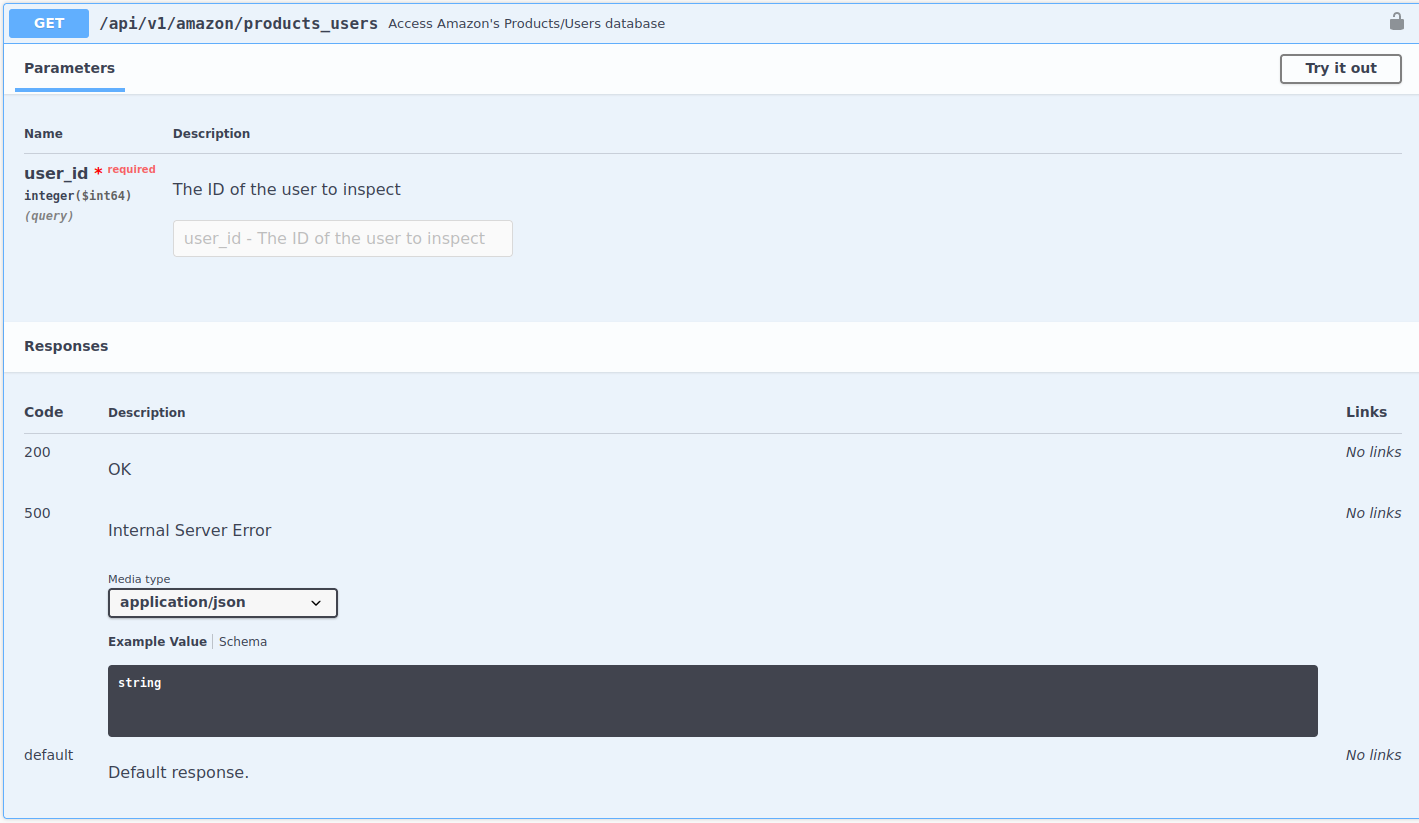
Amazon Books: User Behavior
Link user behavior through different endpoints. Take user
319(see 14.2) and see which other products the user has bought on Amazon.Hidden relationships that you could uncover with the real data set: people who read certain books might have propensities to order certain products
This endpoint needs only one parameter, the user id (int not str)
Amazon Books: User Behavior
resp <-
req %>%
req_url_path_append("products_users") %>%
req_url_query(user_id = 319) %>%
req_perform() %>%
resp_body_json(simplifyVector = TRUE)
resp product_id user_id ean upc
1 74 199 9062391405629 023609654276
image
1 http://placeimg.com/640/480/tech
images
1 Eum odio sit veritatis aut., Aut mollitia ad nam ut., Quos ex fugit voluptatem., Ratione aut quibusdam quia voluptatem. Id unde aut qui doloremque vero cum et. Non amet qui excepturi ut minima autem. Reiciendis soluta aperiam aut dolores voluptatem ipsum., Id est et quas asperiores voluptatum. Ut delectus aspernatur laborum adipisci voluptas. Quo molestiae sed autem corrupti ut optio. Quisquam molestiae dolor iusto repudiandae mollitia quis., Omnis facilis dolor vero. Vel et et temporibus qui debitis aut modi. Saepe provident officiis quod voluptatem et., http://placeimg.com/640/480/any, http://placeimg.com/640/480/any, http://placeimg.com/640/480/any
net_price taxes price
1 298634.4 22 364334.02
tags
1 numquam, blanditiis, inventore, rerum, aut, voluptate, quo, rerum, enimAmazon Books: User Behavior
Info: price, image and tags of the product
Where’s the name? Amazon’s product database…
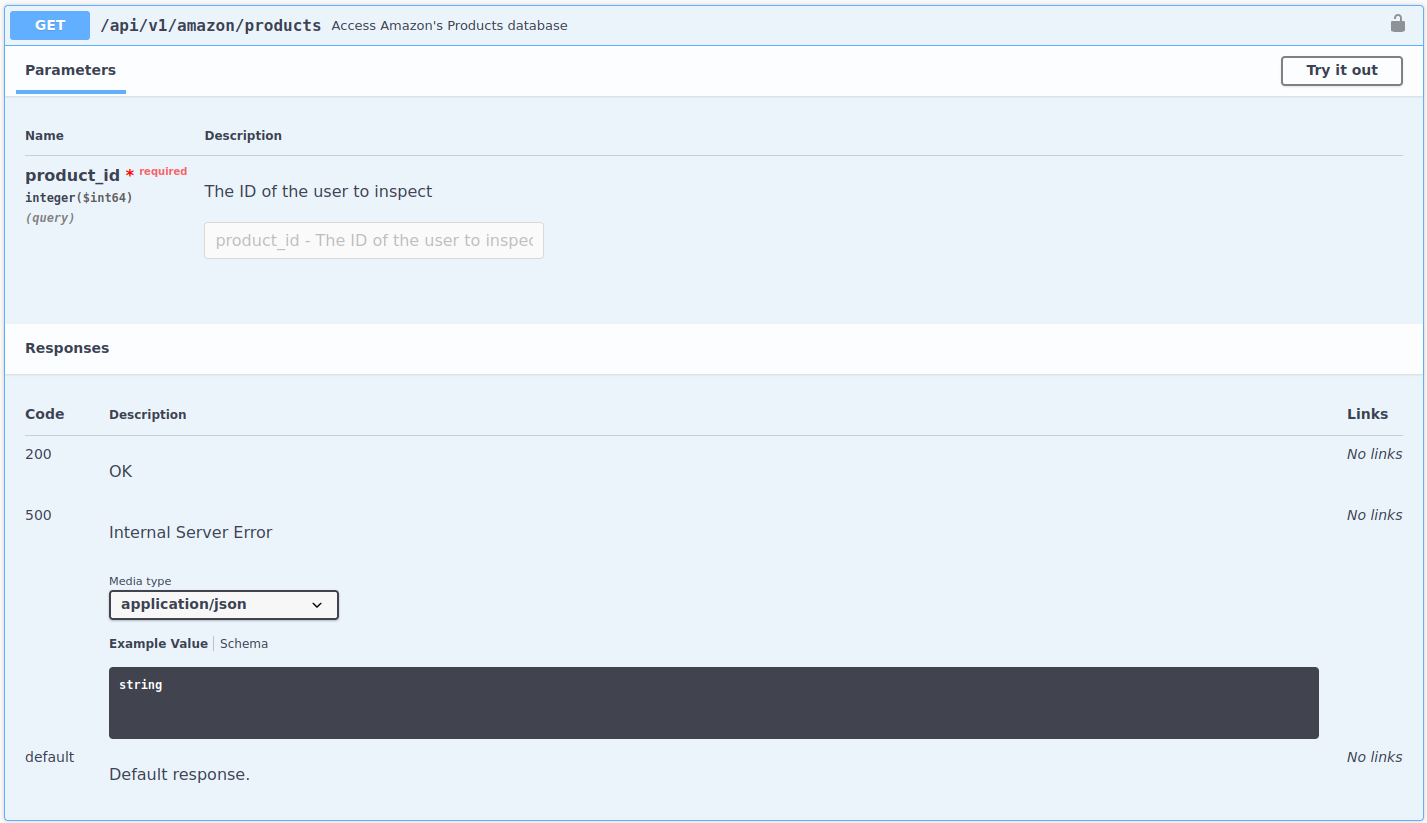
Amazon Books: User Behavior
resp <-
req %>%
req_url_path_append("products") %>%
req_url_query(product_id = 74) %>%
req_perform() %>%
resp_body_json(simplifyVector = TRUE)
resp id name
1 74 Quod qui sit vero vero ad.
description
1 Mollitia ullam animi aut et perspiciatis et tempore ipsa. Quidem praesentium ipsum nihil soluta iusto ducimus nulla.Great, we know the name of the product
Amazon Books: User Behavior
User’s database:
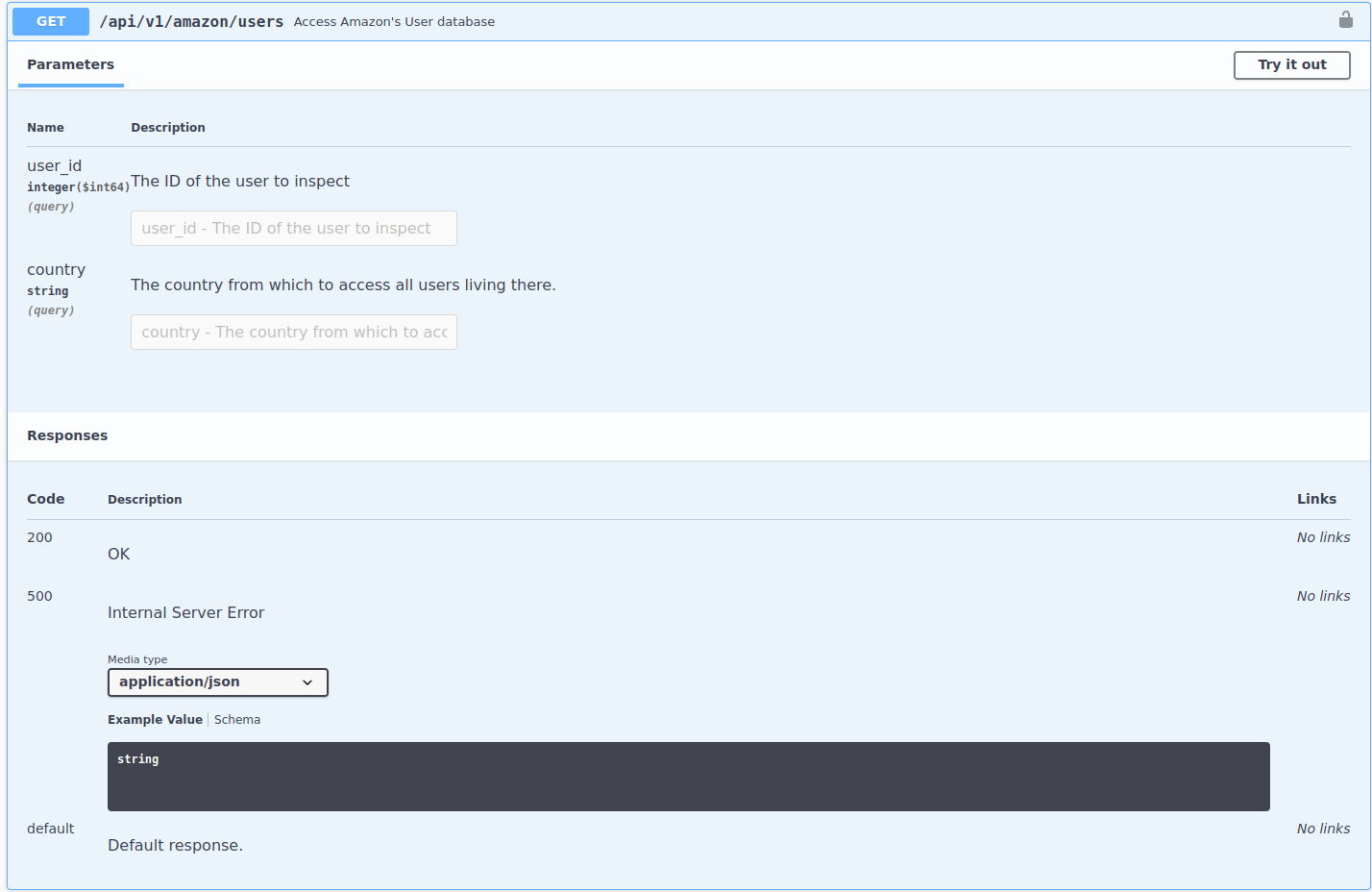
Amazon Books: User Behavior
Needs two arguments
Not required (what?). Only one is required (any of the two).
Different formats: string and integer
Not clear what info you’ll get since the endpoint is too generic: user’s database
Let’s make a query and see what it returns
Amazon Books: User Behavior
resp <-
req %>%
req_url_path_append("users") %>%
req_url_query(user_id = 319) %>%
req_perform() %>%
resp_body_json(simplifyVector = TRUE) %>%
as_tibble()
resp# A tibble: 1 × 4
user_id countries macAddress ip
<int> <chr> <chr> <chr>
1 319 Gambia 73:AE:9F:86:CC:3A 127.77.16.104Alright, we know where the user is from, together with some technical IT info.
Amazon Books: User Behavior
We can replicate the previous one but specify a country:
resp <-
req %>%
req_url_path_append("users") %>%
req_url_query(country = "Germany") %>%
req_perform() %>%
resp_body_json(simplifyVector = TRUE) %>%
as_tibble()
resp# A tibble: 2 × 4
user_id countries macAddress ip
<int> <chr> <chr> <chr>
1 700 Germany 41:5B:FE:BF:21:B4 53.214.36.82
2 505 Germany 31:4E:07:78:81:09 78.141.68.137Summary
Different endpoints return different data + have different access strategies
Some endpoints might be inter-dependent
Documentation of each endpoint is crucial for understanding the API
Better to construct endpoints with functions from the
httr2package
Homework
No homework, focus on final project
Make sure to submit the project ASAP. Will give me more time to revise. Deadline is next class.
Submission of your project will be to paste the Github URL to the repo here.