Ever wondered how you can grab real time data, on demand, without moving a finger?
Welcome to the world of automation!
Automating Web Scraping
One off scraping is just as good
One off scraping will solve many problems as is usually the first starting point
However, you might need this to collect data that is changing constantly
Sometimes you want to gather info the dissappears
Ex: weather data, financial data, sports data, political data
Automating Web Scraping
Automating Web Scraping
Since we want to automate a program, we first need one. Let’s recycle one from our example on El País:
# Load all our librarieslibrary(scrapex)library(xml2)library(magrittr)library(purrr)library(tibble)library(tidyr)library(readr)# If this were being done on the real website of the newspaper, you'd want to# replace the line below with the real link of the website.newspaper_link <-elpais_newspaper_ex()newspaper <-read_html(newspaper_link)all_sections <- newspaper %>%# Find all <section> tags which have an <article> tag# below each <section> tag. Keep only the <article># tags which an attribute @data-dtm-region.xml_find_all("//section[.//article][@data-dtm-region]")final_df <- all_sections %>%# Count the number of articles for each sectionmap(~length(xml_find_all(.x, ".//article"))) %>%# Name all sectionsset_names(all_sections %>%xml_attr("data-dtm-region")) %>%# Convert to data frameenframe(name ="sections", value ="num_articles") %>%unnest(num_articles)
Automating Web Scraping
Our goal with this scraper is to monitor El País
How it distributes news across different categories
The scraper is missing one step: saving the data to CSV.
Logic:
If this is the first time the scraper is run, save a csv file with the count of sections
If the CSV with the count of section exists, open the CSV file and append the newest data with the current time stamp
This approach will add rows with new counts every time the scraper is run.
Automating Web Scraping
library(scrapex)library(xml2)library(magrittr)library(purrr)library(tibble)library(tidyr)library(readr)newspaper_link <-elpais_newspaper_ex()all_sections <- newspaper_link %>%read_html() %>%xml_find_all("//section[.//article][@data-dtm-region]")final_df <- all_sections %>%map(~length(xml_find_all(.x, ".//article"))) %>%set_names(all_sections %>%xml_attr("data-dtm-region")) %>%enframe(name ="sections", value ="num_articles") %>%unnest(num_articles)# Save the current date time as a columnfinal_df$date_saved <-format(Sys.time(), "%Y-%m-%d %H:%M")# Where the CSV will be saved. Note that this directory# doesn't exist yet.file_path <-"~/newspaper/newspaper_section_counter.csv"# *Try* reading the file. If the file doesn't exist, this will silently save an errorres <-try(read_csv(file_path, show_col_types =FALSE), silent =TRUE)# If the file doesn't existif (inherits(res, "try-error")) {# Save the data frame we scraped aboveprint("File doesn't exist; Creating it")write_csv(final_df, file_path)} else {# If the file was read successfully, append the# new rows and save the file againrbind(res, final_df) %>%write_csv(file_path)}
Automating Web Scraping
Summary:
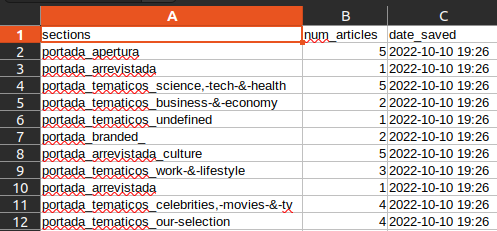
This script will read the website of “El País”
Count the number of sections
Save the results as a CSV file at ~/newspaper/newspaper_section_counter.csv.
That directory still doesn’t exist, so we’ll create it first.
Automating Web Scraping
New tool: The Terminal
Open with CTRL + ALT + t.
Automating Web Scraping
Programatically create directories, files, search for files, execute scripts 🦾
Automating Web Scraping
With the directory created, we copy the R script and check that is there ls
ls ~/newspaper/# newspaper_scraper.R
change directories with the cd command, which stands for changedirectory,
followed by the path where you want to switch to.
For our case, this would be cd ~/newspaper/
Automating Web Scraping
Automating Web Scraping
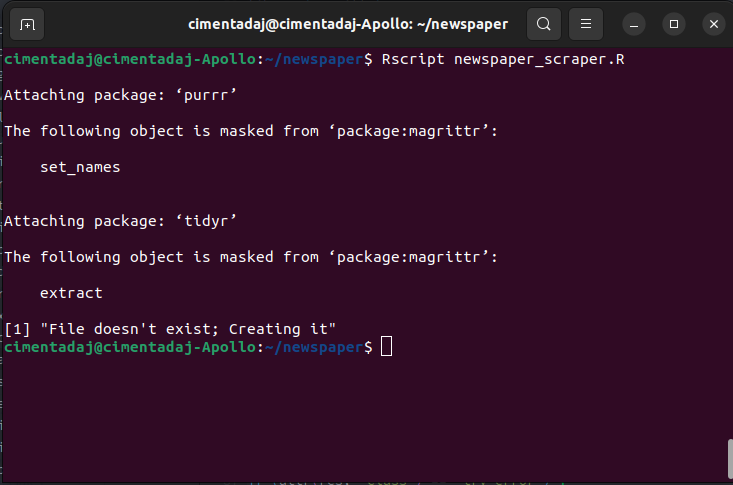
To execute an R script from the terminal you can do it with the Rscript command followed by the file name.
For our case it should be Rscript newspaper_scraper.R
Automating Web Scraping
The first few lines show the printing of package loading
File doesn't exist; Creating it shows how it’s creating the first file
cron, your scheduling friend
Our scraper works
All infrastructure is ready (directories, excel file)
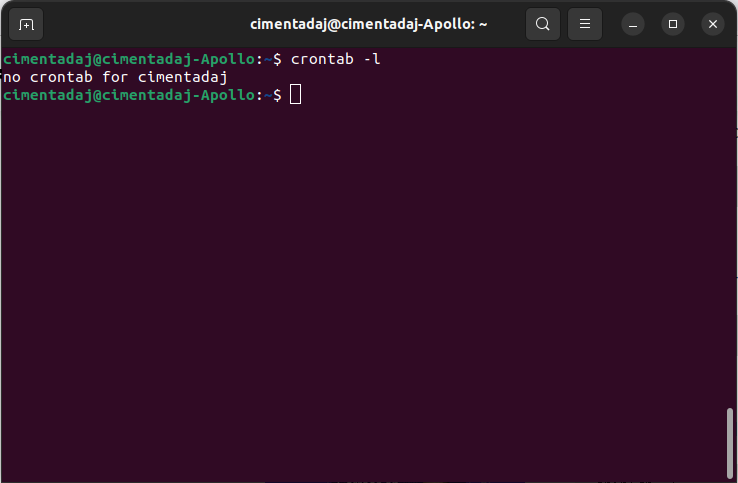
The output means you have no scheduled scripts in your computer.
Anatomy of a schedule
A schedule
What to execute
Rscript ~/newspaper/newspaper_scraper.R
Anatomy of a schedule
* * * * * every minute, hour, of every day of the month, every month, every day of the week.
30 * * * * run at minute 30 of each hour, each day, each month, each day of the week
30 * * * 3 run every 30 minutes on Wednesdays
30 5 * * 6,7 run on the 30th minute of the 5th hour every month on Saturday and Sunday
if day of week, the last slot, clashes in a schedule with the third slot which is day of month then any day matching either the day of month, or the day of week, shall be matched.
Anatomy of a schedule
Let’s say we wanted to run our newspaper scraper every 4 hours, every day, how would it look like?
We have no way of saying, regardless of the day / hour / minute, run the scraper every X hours.
1 */4 * * * run at minute 1 every 4 hours, every day, of the year
1 */4 * * */2 run at minute 1 every 4 hours, every two days
These simple rules will allow you to go very far in scheduling scripts for your scrapers or APIs.
Scheduling our scraper
Schedule our newspaper scraper to run every minute, just to make sure it works.
Will get messy because it’ll append the same resultsin the CSV file continuously.
However, it will give proof that the script is running on a schedule.
If we want this to run every minute, our cron expression should be this * * * * *
Scheduling our scraper
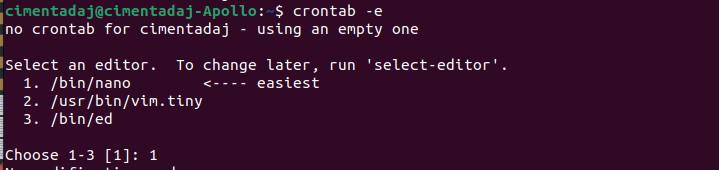
First steps with cron is to pick an editor:
Pick nano, the easiest one.
Scheduling our scraper
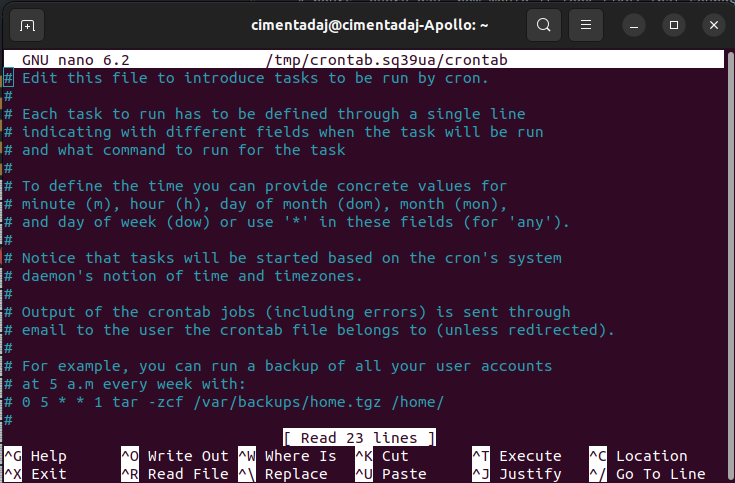
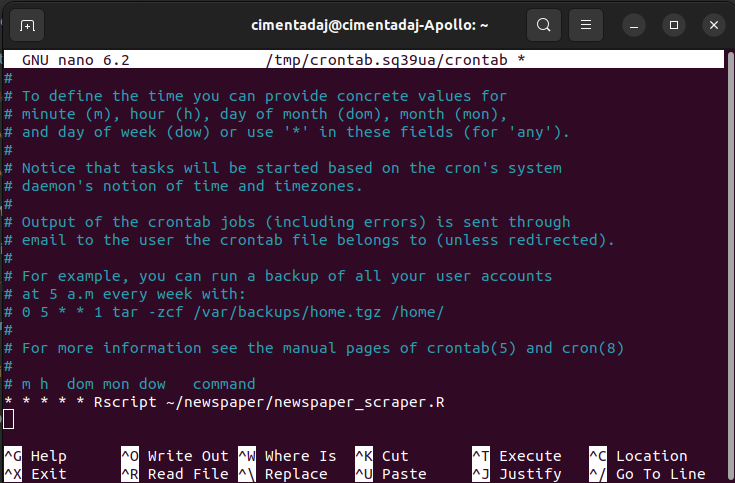
Here is where we write * * * * * Rscript ~/newspaper/newspaper_scraper.R Depending, you might need to add: PATH=/usr/local/bin:/usr/bin:/bin
Scheduling our scraper
Scheduling our scraper
To exit the cron interface, follow these steps:
Hit CTRL and X (this is for exiting the cron interface)
It will prompt you to save the file. PressY to save it.
Press enter to save the cron schedule file with the same name it has.
Nothing special should be happening at the moment. Wait two or three minutes
Scheduling our scraper
Scheduling our scraper
Remove entire line to remove schedule and save again
Caveats
Computer needs to be on all the time; this is why servers are used
cron can also become complex if your schedule patterns are difficult.
Backtracking a failed cron job is tricky because it’s not interactive
Setting up production ready scrapers are difficult: databases, interactivity, persistence, avoid bans, saving data real time, etc..