Login in, scraping and hidden fields
Lightning post. Earlier today I was trying to scrape the emails from all the PhD candidates in my program and I had to log in from our ‘Aula Global’. I did so using httr but something was off: I introduced both my username and password but the website did not log in. Apparently, when loging in through POST, sometimes there’s a thing call hidden fields that you need to fill out! I would’ve never though about this. Below is a case study, that excludes my credentials.
The first thing we have to do is identify the POST method and the inputs to the request. Using Google Chrome, go to the website https://sso.upf.edu/CAS/index.php/login?service=https%3A%2F%2Faulaglobal.upf.edu%2Flogin%2Findex.php and then on the Google Chrome menu go to -> Settings -> More tools -> Developer tools. Here we have the complete html of the website.
- We identify the POST method and the URL
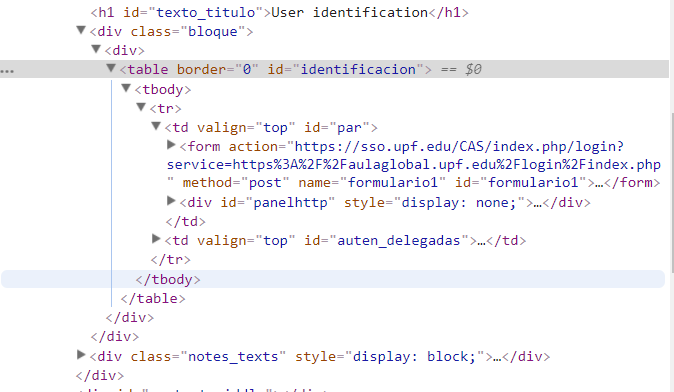
It’s the branch with form that has method='post'.
- Open the
POSTbranch and find all fields. We can see the two ‘hidden’ fields.
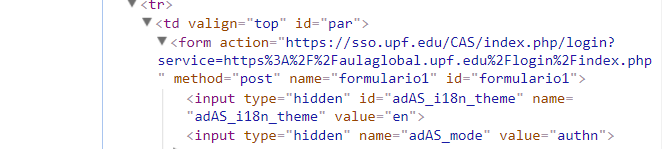
Below the form tag, we see two input tags set to hidden, there they are! Even though we want to login, we also have to provide the two hidden fields. Take note of both their name and value tags.
- Dive deeper down the branch and find other fields. In our case, username and password.
For username:
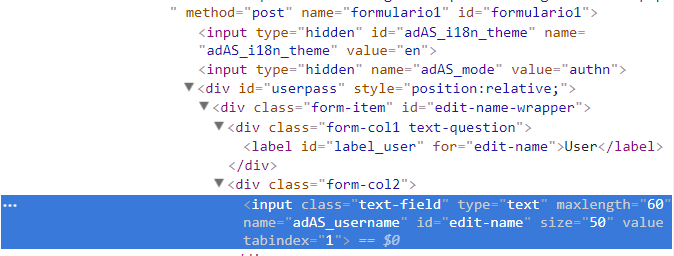
For password:
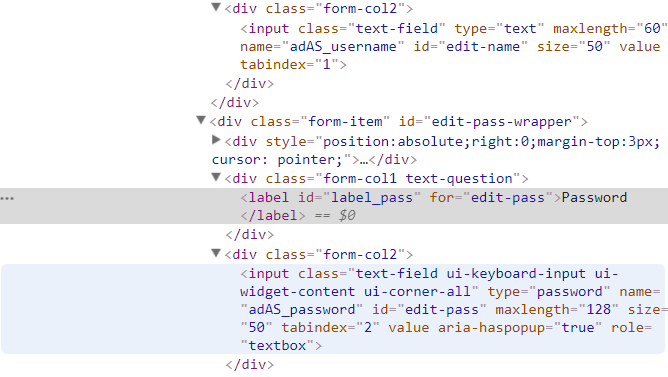
- Write down the field names with the correspoding values.
all_fields <-
list(
adAS_username = "private",
adAS_password = "private",
adAS_i18n_theme = 'en',
adAS_mode = 'authn'
)- Load our packages and our URL’s
library(tidyverse)
library(httr)
library(xml2)
login <- "https://sso.upf.edu/CAS/index.php/login?service=https%3A%2F%2Faulaglobal.upf.edu%2Flogin%2Findex.php"
website <- "https://aulaglobal.upf.edu/user/index.php?page=0&perpage=5000&mode=1&accesssince=0&search&roleid=5&contextid=185837&id=9829"- Login using all of our fields.
upf <- handle("https://aulaglobal.upf.edu")
access <- POST(login,
body = all_fields,
handle = upf)Note how I set the handle. If the website you want to visit and the website that hosts the login information have the same root of the URL (aulaglobal.upf.edu for example), then you can avoid using handle (it’s done behind the scenes). In my case, I set the handle to the same root URL of the website I WANT to visit after I log in (because they have different root URL’s). This way the cookies and login information from the login are preserved through out the session.
- Request the information from the website you’re interested
emails <- GET(website, handle = upf)- Scrape away!
all_emails <-
read_html(emails) %>%
xml_ns_strip() %>%
xml_find_all("//table//a") %>%
as_list() %>%
unlist() %>%
str_subset(".+@upf.edu$")Unfortunately you won’t be able to reproduce this script because you don’t have a log information unless you belong to the same PhD program as I do. However, I hope you find the hidden fields explanation useful, I’m sure I will come back to this in the near future for reference!